Incident management process
Updated
Please use the recommended channels to report security issues, either phone or e-mail. Avoid reporting security issues via public channels.
All security issues are handled according to Kundo's incident management process.
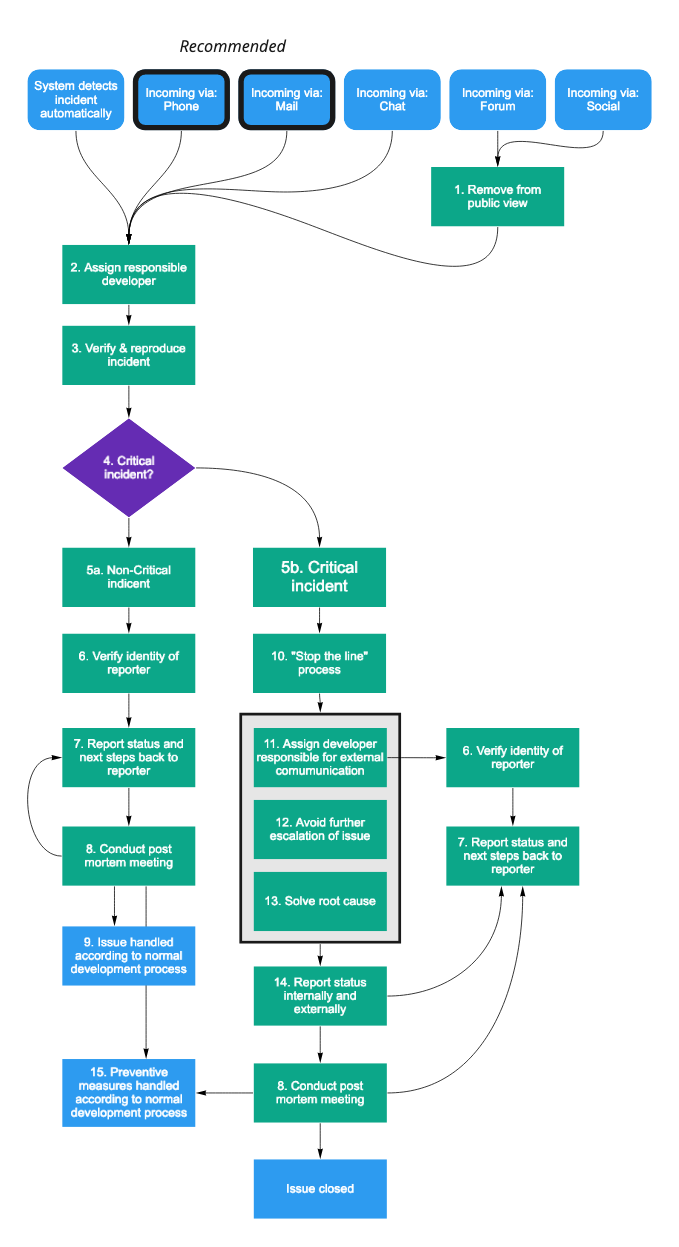
- For an overview of this process, see the below flowchart.
- For details, look up the number in each box, and find the appropriate description below.
Detailed descriptions of each step
For more details about each step, please send an e-mail to security@kundo.se.
- Remove from public view: If the security issue was reported in a public forum instead of via a private channel, always start by removing it from public view. This is meant to limit malicious exploitation of a known security hole.
- Assign responsible developer: Reported incidents are always first assigned to an available developer. This developer is responsible for shepherding the incident through the incident management process.
- Verify & reproduce incident: The first step in assessing the severity of the reported incident is to verify and reproduce it. This could include to ask for clarification from the reporter, examining internal logs, writing code that exploits the incident - with the goal of having a better understanding of the incident that can be reasoned about internally.
- Critical incident? When the issue has been verified, the responsible developer gathers two other developer, and the person in charge of security, and decides if this issue is critical or not.
- Asses incident as either a) Non-critical or b) Criticalbased on the following characteristics:
- Is the privacy of customer data at stake? Yes -> Critical.
- Does this affect the normal operation of our products? Yes -> Critical.
- Is the incident actively exploited? Yes -> Critical.
- Does it only occur during very specific circumstances? Yes -> Non-critical.
- Can this issue lead to more severe follow-up issues if not handled promptly? Yes - Critical.
- Verify the identify of the reporter. Before reporting the results of our assessment of the situation the reporters identify should always be verified. This ensures information about that specific customer can be shared with the reporter, something that never should be done without verification. Verification can be accomplished in many different ways, the easiest being reestablishing contact with the reporter using public information (e.g. calling a number found on the public website or a (verified) e-mail signature).
- Report status and next steps back to the reporter. During the whole process of handling an incident, the reporter (and everyone affected by it) should be kept in the loop about what the status is. This is especially true after assessing of the incident is critical or not and when the issue has been resolved.
- Conduct post mortem meeting. During a post mortem the people involved in handling the issue gathers and tries to summarize the incident according to the following questions:
- Under which circumstances did the incident occur?
- What happened and how did Kundo respond?
- What went wrong? What checks failed?
- In what way did or processes and technology fail?
- In what way did or processes and technology work well?
- Based on this: what changes to processes or technology are we planning to do?
- Does knowledge about this issue need to be spead wider within the company?
- Has the issue been documented according to what it's severity demands?
- Issue handled according to normal development process. If the issue is deemed Non-critical it's handled as other incoming requests. These are prioritized by either the head of product or one of the team leads.
- "Stop the line" process: When a critical security incident is confirmed, a specific process in the development team is triggered. All current development is halted and the full team gathers to respond to the incident.
- Assign a developer responsible for external communication. During the handling of an incident it's important to be transparent of the status and progress towards solving it, both internally and externally. To ensure this happens, one developer does not take part in actual troubleshooting, but instead just reports the status externally, in a way that is as free of technical jargon as possible.
- Avoid further escalation of issue. The first point of order in handling an incident is trying to contain it, and avail escalation. This could include disabling parts of the system, or temporarily limiting access. It's not meant to be the final solution to the problem, but to limit it's spread, and ensure the impact is as small as possible.
- Solve root cause. When the incident has been contained, a fix for the root cause is attempted. When this is done, all systems should be back to normal, and any limitations to the system introduced in 12) should be removed.
In rare cases, the containment of the issue in 12) is enough to deescalate the issue from critical to non-critical. In that case, fixing the root cause can be postponed until later. - Report status internally and externally. When the incident is resolved everyone involved needs to be updated in the status of the issue. The exact communication practices depends on legislation, the nature of the incident, and whose data was affected.
This process is regularly updated based on learnings from the post mortem meetings.